|
Suppose we have a data set {x_1,…,x_N} consisting of N observations of a random D-dimensional Euclidean variable X. Our goal is to partition the data set into some number K of clusters. We define 〖μ=〖{μ〗_1,…,μ〗_k} as the centers of clusters, s={s_1,…,s_k} indicate the assignments of x. 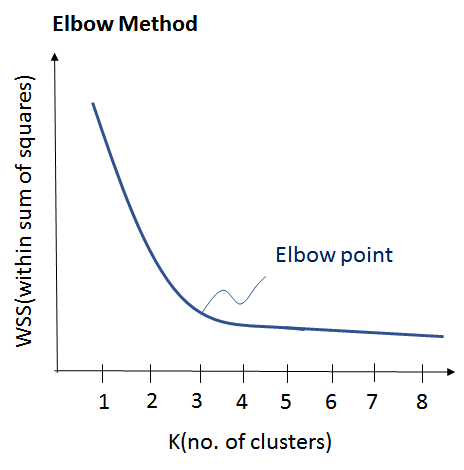 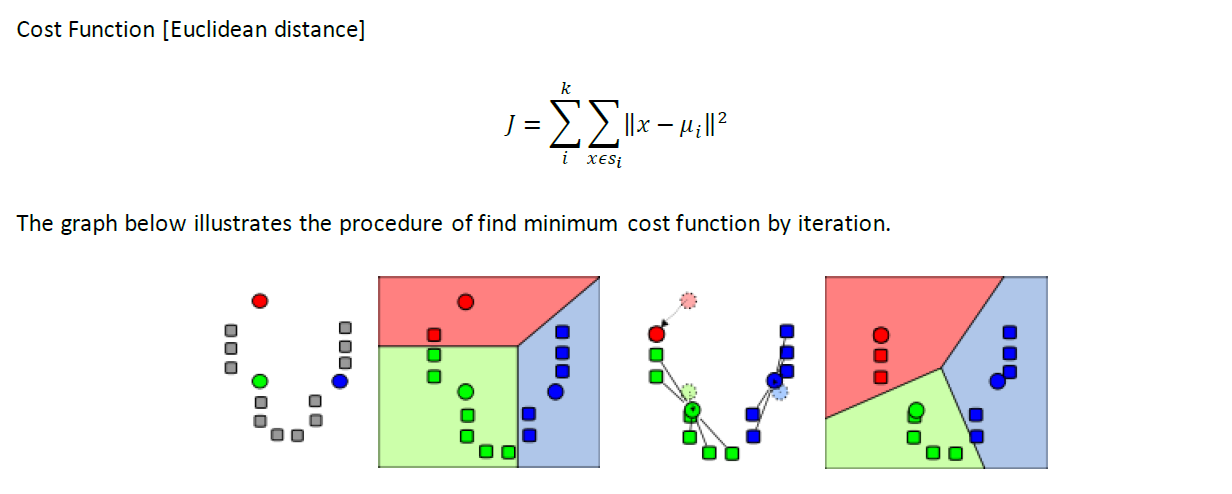
0 Comments
|
